|
2.1.
Типы файловых систем, поддерживаемых в Линукс
2.2.
Структура дискового раздела в ext2fs
2.3.
Индексные дескрипторы файлов
2.4.
Система адресации данных
2.5.
VFS
2.6.
Новые файловые системы
2.7.
Журналируемые файловые системы
2.8.
Файловая система ReiserFS
Литература
Как уже было сказано , файловая система - одна из основных
составных частей любой операционной системы, так как она обеспечивает хранение
информации на физических носителях и доступ приложений к этой информации. В
разделе 4 была достаточно подробно рассмотрена та сторона файловой системы,
которая обращена к пользователю - логическая структура каталогов и файлов. В
этом разделе мы рассмотрим внутренние механизмы работы файловых систем, то есть
обратную (невидимую для пользователя) сторону файловой системы. Эта сторона
обращена к физическим устройствам и определяет способ хранения информации на
носителях и механизмы записи и извлечения этой информации по запросам
приложений. Здесь в основе всего лежит способ адресации отдельных участков
носителя и механизмы размещения отрезков файла по этим участкам.
Но, прежде чем перейти к описанию конкретных механизмов, стоит отметить, что
Линукс умеет работать с несколькими типами файловых систем. Основной файловой
системой для Линукс является "вторая расширенная файловая система" (second
extended filesystem), которую кратко обозначают как ext2fs. Именно ее
механизмы будут подробно рассматриваться в настоящем разделе. Но прежде, чем
перейти к ее рассмотрению, ненадолго отвлечемся для того, чтобы перечислить
некоторые типы файловых систем, которые поддерживаются в Линукс. Эту табличку
нельзя считать полной по той простой причине, что работа по созданию новых типов
файловых систем для Линукс продолжается постоянно. Примером вновь
разрабатываемых файловых систем являются журналируемая файловая система JFS
фирмы IBM, файловая система ReiserFS. Эти системы и их отличия от основной на
настоящий момент файловой системы Линукс, ext2fs, мы постараемся
рассмотреть в конце этого раздела.
2.1. Типы файловых систем, поддерживаемых в Линукс
В этой табличке мы просто кратко перечисляются основные типы файловых систем, с
которыми может работать Линукс. А теперь подробнее рассмотрим основной на
сегодняшний день тип файловой системы для Линукс - ext2fs.("Научить"
Линукс использовать эти и другие ФС можно после переконфигурирования ядра ОС)
| Тип |
Назначение |
| minix |
Файловая система minix - это первая файловая система, которая
использовалась в Линукс. Она имела массу недостатков: ограничения размера
раздела жесткого диска 64 мегабайтами; длина имени файла была ограничена
30 символами и т.д. Она продолжает использоваться для дискет и RAM-дисков.
|
| extfs |
Еще одна из ранних версий файловой системы для Linux, расширение
файловой системы minix. В настоящее время заменена файловой системой ext2
и уже не используются |
| ext2fs |
Вторая расширенная файловая система (second extended filesystem) была
создана как расширение расширенной файловой системы (extfs). ext2fs
обеспечивает более высокую производительность (в части скорости и
использования центрального процессора), поддерживаются длинные имена и
большие размеры файлов. |
| xiaf |
Файловая система Xiaf была создана на основе minix с целью обеспечения
большей устойчивости и безопасности. Она обеспечивает выполнение основных
функций файловой системы без излишней сложности. |
| msdos |
Файловая система, используемая для разделов, сформатированных в MS-DOS
и Windows. Имена файлов в msdos должны удовлетворять стандарту 8.3. |
| umsdos |
Файловая система UMS-DOS является расширением файловой системы DOS,
используемым под Linux. В ней добавлено использование длинных имен файлов,
идентификаторы пользователя и группы (UID/GID), разрешения в стиле POSIX и
специальные файлы (устройства, именованные каналы и т.д.) при этом
совместимость с DOS не потеряна. |
| hpfs |
Файловая система для разделов OS/2. В Линукс обеспечивается только
чтение из разделов hpfs. |
| proc |
Это файловая система, которая используется для обращения к структурам
данных ядра. Файлы этой системы не занимают дискового пространства.
Подробнее см. man proc(5). |
| nfs |
Сетевая файловая система, используемая для доступа к дискам,
расположенным на удаленных компьютерах. |
| swap |
Раздел или файл свопинга OC Linux |
| sysv |
Файловая система Unix Systen V. Она поддерживает файловые системы
Xenix FS, SystemV/386 FS и Coherent FS. |
| iso9660 |
Файловая система для монтирования CD-ROM, соответствующая стандарту
ISO 9660. |
| vfat |
Файловая система FAT-32. Поддерживаются длинные имена файлов. |
| smb |
Это сетевая файловая система, которая поддерживает протокол SMB,
используемый Windows, Windows NT и Lan Manager. Для того, чтобы
использовать эту файловую систему, надо иметь специальную программу
монтирования smbmount. |
| ncpfs |
Это сетевая файловая система, обеспечивающая поддержку протокола NCP,
применяемого в Novell NetWare. Для того, чтобы использовать эту файловую
систему, надо тоже иметь специальную программу, которую можно найти на
сайте ftp://linux01.gwdg.de/pub/ncpfs. |
2.2. Структура дискового раздела в ext2fs
Производители жестких
дисков обычно поставляют свои изделия отформатированными на низком уровне.
Насколько я знаю, это означает, что все дисковое пространство с помощью
специальных меток разбито на "сектора", размером 512 байт. Такой диск (или
дисковый раздел) должен быть подготовлен для использования в определенной
операционной системе. В MS-DOS или Windows процедура подготовки называется
форматированием, а в Линукс - созданием файловой системы. Создание файловой
системы ext2fs заключается в создании в разделе диска определенной
логической структуры. Эта структура строится следующим образом. Во-первых, на
диске выделяется загрузочная область(рис. 2.). Загрузочная область создается в любой
файловой системе. На первичном разделе она содержит загрузочную запись -
фрагмент кода, который инициирует процесс загрузки операционной системы при
запуске. На других разделах эта область не используется. Все остальное
пространство на диске делится на блоки. Блок может иметь размер от 1, 2 или 4
килобайта. Блок является адресуемой единицей дискового пространства. Выделение
места файлам осуществляется целыми блоками, поэтому при выборе размера блока
приходится идти на компромисс. Большой размер блока, как правило, сокращает
число обращений к диску при чтении или записи файла, но зато увеличивает долю
нерационально используемого пространства, особенно, при наличии большого числа
файлов маленького размера.

Рис.2. Структура EXT2FS
Блоки, в свою область объединяются в группы блоков(ext2fs). Группы блоков в файловой
системе и блоки внутри группы нумеруются последовательно, начиная с 1. Первый
блок на диске имеет номер 1 и принадлежит группе с номером 1. Общее число блоков
на диске (в разделе диска) является делителем объема диска, выраженного в
секторах. А число групп блоков не обязано делить число блоков, потому что
последняя группа блоков может быть не полной. Начало каждой группы блоков имеет
адрес, который может быть получен как ((номер группы - 1)* (число блоков в
группе)).
Каждая группа блоков имеет одинаковое строение. Ее структура представлена в
следующей табличке.
ext2fs
| Суперблок |
| Group Descriptors |
| Block Bitmap |
| INode Bitmap |
Таблица индексных дескрипторов
(INode
Table)
|
Область блоков
данных
|
Первый элемент этой структуры (суперблок) - одинаков для всех групп, а все
остальные - индивидуальны для каждой группы. Суперблок хранится в первом блоке
каждой группы блоков (за исключением группы 1, в которой в первом блоке
расположена загрузочная запись). Суперблок является начальной точкой файловой
системы. Он имеет размер 1024 байта и всегда располагается по смещению 1024
байта от начала файловой системы. Наличие нескольких копий суперблока
объясняется чрезвычайной важностью этого элемента файловой системы. Дубликаты
суперблока используются при восстановлении файловой системы после сбоев.
Информация, хранимая в суперблоке, используется для организации доступа к
остальным данным на диске. В суперблоке определяется размер файловой системы,
максимальное число файлов в разделе, объем свободного пространства и содержится
информация о том, где искать незанятые участки. При запуске ОС суперблок
считывается в память и все изменения файловой системы вначале находят
отображение в копии суперблока, находящейся в ОП, и записываются на диск только
периодически. Это позволяет повысить производительность системы, так как многие
пользователи и процессы постоянно обновляют файлы. С другой стороны, при
выключении системы суперблок обязательно должен быть записан на диск, что не
позволяет выключать компьютер простым выключением питания. В противном случае,
при следующей загрузке информация, записанная в суперблоке, окажется не
соответствующей реальному состоянию файловой системы.
Суперблок имеет структуру, которая представлена в
нижеследующей таблице
| Название поля |
Тип |
Комментарий |
| s_inodes_count |
ULONG |
Число индексных дескрипторов в файловой
системе |
| s_blocks_count |
ULONG |
Число блоков в файловой системе |
| s_r_blocks_count |
ULONG |
Число блоков, зарезервированных для
суперпользователя
|
| s_free_blocks_count |
ULONG |
Счетчик числа свободных блоков |
| s_free_inodes_count |
ULONG |
Счетчик числа свободных индексных
дескрипторов |
| s_first_data_block |
ULONG |
Первый блок, который содержит данные. В зависимости
от размера блока, это поле может быть равно 0 или 1. |
| s_log_block_size |
ULONG |
Индикатор размера логического блока: 0 = 1 Кб; 1 = 2
Кб; 2 = 4 Кб. |
| s_log_frag_size |
LONG |
Индикатор размера фрагментов (кажется, понятие
фрагмента в настоящее время не используется) |
| s_blocks_per_group |
ULONG |
Число блоков в каждой группе блоков |
| s_frags_per_group |
ULONG |
Число фрагментов в каждой группе блоков |
| s_inodes_per_group |
ULONG |
Число индексных дескрипторов (inodes) в каждой группе
блоков |
| s_mtime |
ULONG |
Время, когда в последний раз была смонтирована
файловая система. |
| s_wtime |
ULONG |
Время, когда в последний раз производилась запись в
файловую систему |
| s_mnt_count |
USHORT |
Счетчик числа монтирований файловой системы. Если
этот счетчик достигает значения, указанного в следующем поле
(s_max_mnt_count), файловая система должна быть проверена (это делается
при перезапуске), а счетчик обнуляется.
|
| s_max_mnt_count |
SHORT |
Число, определяющее, сколько раз может быть
смонтирована файловая система |
| s_magic |
USHORT |
"Магическое число" (0xEF53), указывающее, что
файловая система принадлежит к типу ex2fs |
| s_state |
USHORT |
Флаги, указывающее текущее состояние файловой системы
(является ли она чистой (clean) и т.п.) |
| s_errors |
USHORT |
Флаги, задающие процедуры обработки сообщений об
ошибках (что делать, если найдены ошибки). |
| s_pad |
USHORT |
Заполнение |
| s_lastcheck |
ULONG |
Время последней проверки файловой системы
|
| s_checkinterval |
ULONG |
Максимальный период времени между проверками файловой
системы |
| s_creator_os |
ULONG |
Указание на тип ОС, в которой создана файловая
система |
| s_rev_level |
ULONG |
Версия (revision level) файловой системы.
|
| s_reserved |
ULONG[235] |
Заполнение до 1024 байт |
Вслед за суперблоком расположено описание группы блоков (Group Descriptors).
Это описание представляет собой массив, имеющий следующую структуру.
| Название поля |
Тип |
Назначение |
| bg_block_bitmap |
ULONG |
Адрес блока, содержащего битовую карту блоков (block
bitmap) данной группы |
| bg_inode_bitmap |
ULONG |
Адрес блока, содержащего битовую карту индексных
дескрипторов (inode bitmap) данной группы |
| bg_inode_table |
ULONG |
Адрес блока, содержащего таблицу индексных
дескрипторов (inode table) данной группы |
| bg_free_blocks_count |
USHORT |
Счетчик числа свободных блоков в данной группе
|
| bg_free_inodes_count |
USHORT |
Число свободных индексных дескрипторов в данной
группе |
| bg_used_dirs_count |
USHORT |
Число индексных дескрипторов в данной группе, которые
являются каталогами |
| bg_pad |
USHORT |
Заполнение |
| bg_reserved |
ULONG[3] |
Заполнение |
Размер описания группы блоков можно вычислить как
(размер_группы_блоков_в_ext2 * число_групп) / размер_блока (при
необходимости округляем).
Информация, которая хранится в описании группы, используется для того, чтобы
найти битовые карты блоков и индексных дескрипторов, а также таблицу индексных
дескрипторов. Не забывайте, что блоки и группы блоков нумеруются начиная с 1.
Битовая карта блоков (block bitmap) - это структура, каждый бит которой
показывает, отведен ли соответствующий ему блок какому-либо файлу. Если бит
равен 1, то блок занят. Эта карта служит для поиска свободных блоков в тех
случаях, когда надо выделить место под файл, Битовая карта блоков занимает число
блоков, равное (число_блоков_в_группе / 8) / размер_блока (при
необходимости округляем).
Битовая карта индексных дескрипторов выполняет аналогичную функцию по
отношению к таблице индексных дескрипторов: показывает какие именно дескрипторы
заняты.
Следующая область в структуре группы блоков служит для хранения таблицы
индексных дескрипторов файлов. Структура самого индексного дескриптора подробнее
рассматривается в следующем подразделе.
Ну, и наконец, все оставшееся место в группе блоков отводится для хранения
собственно файлов.
2.3. Индексные дескрипторы файлов
Каждому файлу на диске соответствует
один и только один индексный дескриптор файла, который идентифицируется своим
порядковым номером - индексом файла. Это означает, что число файлов, которые
могут быть созданы в файловой системе, ограничено числом индексных дескрипторов,
которое либо явно задается при создании файловой системы, либо вычисляется
исходя из физического объема дискового раздела.
Индексный дескриптор файла имеет следующее строение:
| Название поля |
Тип |
Описание |
| i_mode |
USHORT |
Тип и права доступа к данному файлу. |
| i_uid |
USHORT |
Идентификатор владельца файла (Owner
Uid). |
| i_size |
ULONG |
Размер файла в байтах. |
| i_atime |
ULONG |
Время последнего обращения к файлу (Access
time). |
| i_ctime |
ULONG |
Время создания файла. |
| i_mtime |
ULONG |
Время последней модификации файла. |
| i_dtime |
ULONG |
Время удаления файла. |
| i_gid |
USHORT |
Идентификатор группы (GID). |
| i_links_count |
USHORT |
Счетчик числа связей (Links count). |
| i_blocks |
ULONG |
Число блоков, занимаемых файлом. |
| i_flags |
ULONG |
Флаги файла (File flags) |
| i_reserved1 |
ULONG |
Зарезервировано для ОС |
| i_block |
ULONG[15] |
Указатели на блоки, в которых записаны данные файла
(это поле подробно описано в разделе 21.4) |
| i_version |
ULONG |
Версия файла (для NFS) |
| i_file_acl |
ULONG |
ACL файла |
| i_dir_acl |
ULONG |
ACL каталога |
| i_faddr |
ULONG |
Адрес фрагмента (Fragment address) |
| i_frag |
UCHAR |
Номер фрагмента (Fragment number) |
| i_fsize |
UCHAR |
Размер фрагмента (Fragment size) |
| i_pad1 |
USHORT |
Заполнение |
| i_reserved2 |
ULONG[2] |
Зарезервировано |
Поле типа и прав доступа к файлу представляет собой двух-байтовое слово,
каждый бит которого служит флагом, индицирующим отношение файла к определенному
типу или установку одного конкретного права на файл.
| Идентификатор |
Значение |
Назначение флага (поля) |
| S_IFMT |
F000 |
Маска для типа файла |
| S_IFSOCK |
A000 |
Доменное гнездо (socket) |
| S_IFLNK |
C000 |
Символическая ссылка |
| S_IFREG |
8000 |
Обычный (regular) файл |
| S_IFBLK |
6000 |
Блок-ориентированное устройство |
| S_IFDIR |
4000 |
Каталог |
| S_IFCHR |
2000 |
Байт-ориентированное (символьное)
устройство |
| S_IFIFO |
1000 |
Именованный канал (fifo) |
| |
|
|
| S_ISUID |
0800 |
SUID - бит смены владельца |
| S_ISGID |
0400 |
SGID - бит смены группы |
| S_ISVTX |
0200 |
Бит сохранения задачи (sticky bit) |
| |
|
|
| S_IRWXU |
01C0 |
Маска прав владельца файла |
| S_IRUSR |
0100 |
Право на чтение |
| S_IWUSR |
0080 |
Право на запись |
| S_IXUSR |
0040 |
Право на выполнение |
| |
|
|
| S_IRWXG |
0038 |
Маска прав группы |
| S_IRGRP |
0020 |
Право на чтение |
| S_IWGRP |
0010 |
Право на запись |
| S_IXGRP |
0008 |
Право на выполнение |
| |
|
|
| S_IRWXO |
0007 |
Маска прав остальных пользователей |
| S_IROTH |
0004 |
Право на чтение |
| S_IWOTH |
0002 |
Право на запись |
| S_IXOTH |
0001 |
Право на выполнение |
Среди индексных дескрипторов имеется несколько дескрипторов, которые
зарезервированы для специальных целей и играют особую роль в файловой системе.
Это следующие дескрипторы
| Идентификатор |
Значение |
Описание |
| EXT2_BAD_INO |
1 |
Индексный дескриптор, в котором перечислены адреса
дефектных блоков на диске (Bad blocks inode) |
| EXT2_ROOT_INO |
2 |
Индексный дескриптор корневого каталога файловой
системы (Root inode) |
| EXT2_ACL_IDX_INO |
3 |
ACL inode |
| EXT2_ACL_DATA_INO |
4 |
ACL inode |
| EXT2_BOOT_LOADER_INO |
5 |
Индексный дескриптор загрузчика (Boot loader
inode) |
| EXT2_UNDEL_DIR_INO |
6 |
Undelete directory inode |
| EXT2_FIRST_INO |
11 |
Первый незарезервированный индексный
дескриптор |
Самый важный дескриптор в этом списке - дескриптор корневого каталога. Этот
дескриптор указывает на корневой каталог, который, подобно всем каталогам,
состоит из записей следущей структуры:
| Название поля |
Тип |
Описание |
| inode |
ULONG |
номер индексного дескриптора (индекс)
файла |
| rec_len |
USHORT |
Длина этой записи |
| name_len |
USHORT |
Длина имени файла |
| name |
CHAR[0] |
Имя файла |
Отдельная запись в каталоге не может пересекать границу блока (то есть должна
быть расположена целиком внутри одного блока). Поэтому, если очередная запись не
помещается целиком в данном блоке, она переносится в следующий блок, а
предыдущая запись продолжается таким образом, чтобы она заполнила блок до конца.
2.4. Система адресации данных
Система адресации данных - это одна из
самых существенных составных частей файловой системы. Именно система адресации
позволяет находить нужный файл среди множества как пустых, так и занятых блоков
на диске. В ext2fs система адресации реализуется полем i_block
индексного дескриптора файла.
Поле i_block в индексном дескрипторе файла представляет собой массив
из 15 адресов блоков. Первые 12 адресов в этом массиве (EXT2_NDIR_BLOCKS [12])
представляют собой прямые ссылки (адреса) на номера блоков, в которых хранятся
данные из файла. Следующий адрес в этом массиве (EXT2_IND_BLOCK) является
косвенной ссылкой, то есть адресом блока, в котором хранится список адресов
следующих блоков с дан
ными из этого файла. В этом блоке могут быть записаны
адреса (размер_блока / размер_ULONG) блоков с данными файла.
Следующий адрес в поле i_block индексного дескриптора
(EXT2_DIND_BLOCK) указывает на блок двойной косвенной адресации (double indirect
block). Этот блок содержит список адресов блоков, которые в свою очередь
содержат списки адресов следующих блоков данных того файла, который задается
данным индексным дескриптором.
И, наконец, последний адрес (EXT2_TIND_BLOCK) в поле i_block
индексного дескриптора задает адрес блока тройной косвенной адресации, то есть
блока со списком адресов блоков, которые являются блоками двойной косвенной
адресации.
Теперь Вы знаете, как устроены индексные дескрипторы файлов, то есть знаете,
как в файловой системе ext2fs осуществляется запись в файл и чтение из
файла.
Может быть здесь еще надо бы рассказать о команде mkfs, которая служит
для создания файловой системы в разделе диска. , а
за более подробными пояснениями читатель может обратиться к интерактивным
руководствам.
2.5. Виртуальная файловая система VFS
До сих пор наш рассказ о файловой системе касался только "статических", если
можно так выразиться, составных частей файловой системы. Но, я думаю, Вы
понимаете, что все это хозяйство обслуживается какими-то программными модулями.
Эти программные части можно разделить на две составных части. Одна часть входит
в состав ядра и образует так называемую виртуальную файловую систему VFS (рис.
3). VFS обеспечивает унифицированный
программный интерфейс к услугам файловой системы, причем безотносительно к тому,
какой тип файловой системы (vfat, ext2fs, nfs и т.д.) имеется на конкретном
физическом носителе. Поэтому каждая файловая система должна предоставлять еще
какие-то конкретные процедуры доступа к своим файлам, для того, чтобы
использоваться под Линукс. Виртуальная файловая система VFS, расположенная как
бы между приложениями и конкретными файловыми системами, позволяет
пользовательским приложениям получать доступ к множеству файловых систем разных
типов
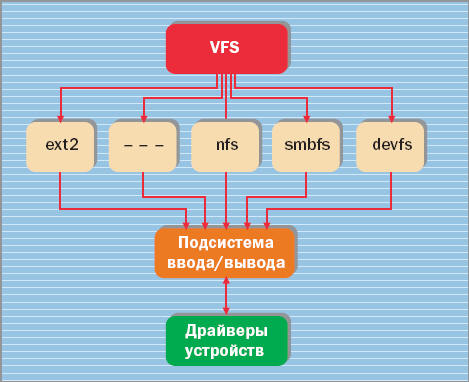
Рис.3. Схема Virtual File System
2.6. Новые файловые системы
Файловая система ext2fs была создана по образу и подобию файловой
системы UNIX (UNIX File System - UFS). Обе они (особенно UFS) создавались еще в
те времена, когда диски и другие физические носители данных имели довольно
маленький (по современным меркам) объем. Увеличение объема дисков вело к
возрастанию объема разделов диска, увеличению размеров отдельных файлов и
каталогов. Это породило ряд проблем, связанных с ограниченностью внутренних
структур данных файловой системы.
Существуют две основных проблемы этого рода:
- Эти структуры не способны работать с носителями информации увеличенного
объема. В них отведено строго фиксированное число бит для хранения данных о
размере дисковых разделов и размерах файлов, фиксированное число бит для
хранения логических номеров блоков и так далее. Как следствие, число файлов
и каталогов и их размер ограничены.
- Вторая проблема связана с производительностью. В силу заложенных в
старые файловые системы алгоритмов решение некоторых задач на носителях
увеличенного объема стало требовать слишком большого времени. Одним из самых
характерных примеров такого рода проблем является трудоемкость
восстановления файловой системы после сбоев (например, после неожиданного
отключения питания). Это восстановление выполняется с помощью программы
fsck и для очень больших дисков стало требовать нескольких часов.
Естественно, что появление этих проблем породило и попытки их решения. Были
разработаны новые типы файловых систем, при создании которых учитывались
требования масштабируемости. Наиболее известными разработками файловых систем
новых типов являются:
В следующей табличке приведены данные по увеличению основных параметров,
обеспечиваемых новыми файловыми системами. Данные заимствованы из статьи Juan I.
Santos Florido "Journal File Systems", опубликованной в 55-ом выпуске Linux
Gazette (July 2000).
| |
Размер блока
|
Максим.
размер файловой системы |
Максим.
размер файла |
| Ext3FS
|
1KB-4KB
|
4Tb
|
2GB
|
| XFS
|
от 512 байт
до 64 KB |
18 тысяч
петабайт |
9 тысяч
петабайт |
| JFS
|
512, 1024, 2048, 4096 байт
|
от 4 петабайт
(при 512-байтных блоках) до 32 петабайт (при 4-килобайтовых блоках)
|
от 512
терабайт (при 512-байтовых блоках) до 4 петабайт (при 4-килобайтовых
блоках) |
| ReiserFS
|
До 64KB
Пока что фиксирован, 4KB |
4GB of
blocks, 16 Tb |
4GB, 2^10
petabytes in ReiserFS (3.6.xx) |
2.7. Журналируемые файловые системы
Основная цель, которая преследуется при создании журналируемых файловых
систем, насколько я понял, состоит в том, чтобы обеспечить быстрое
восстановление системы после сбоев (например, после потери питания). Дело в том,
что если произойдет такой сбой, то часть информации о расположении файлов
теряется, поскольку не все изменения сразу записываются на диск. После этого
программа fsck вынуждена просматривать весь диск блок за блоком
(пользуясь битовыми матрицами занятых блоков и индексных дескрипторов) с целью
восстановления потерянных связей. При увеличении размера дисков вдвое, вдвое
увеличивается и время, необходимое для просмотра всего диска. А при тех объемах,
которых достигают современные диски, особенно на серверах, время, необходимое
для того, чтобы просмотреть весь диск, стало недопустимо велико: оно стало
достигать часов и даже суток. А сервер в это время не отзывается! Кроме того,
нет гарантии, что все связи удастся восстановить.
В журналируемых файловых системах для решения этой проблемы применяют технику
транзакций, развитую в теории баз данных. Суть этой техники в том, что действие
не считается завершенным, пока все изменения не сохранены на диске. А чтобы
сбои, происходящие в течение времени, необходимого для завершения всех операций,
не приводили к необратимым последствиям, все действия и все изменяемые данные
протоколируются. Если сбой все-таки произойдет, то по этому протоколу можно
вернуть систему в безошибочное состояние.
Главное отличие в технике транзакций, применяемой в базах данных, от
аналогичной техники, применяемой в журналируемых файловых системах, состоит в
том, что в базах данных сохраняются в протоколе как сами изменяемые данные, так
и вся управляющая информация, в то время как понятие транзакции в файловых
системах подразумевает сохранение только мета-данных: индексных дескрипторов
изменяемого файла, битовых карт распределения свободных блоков и свободных
индексных дескрипторов. Дело в том, что если сохранять все изменяемые данные, то
теряется смысл кеширования записи на диск и уменьшается скорость дисковых
операций. Мета-данные же, во-первых, меньше по размеру, а, во-вторых,
сохраняются в специально выделенной области диска, что позволяет избежать
чрезмерных затрат времени на ведение протокола.
Файловые системы ext3fs и JFS являются журналируемыми. Надо
отметить, что ext3fs не является совершенно новой разработкой, а является
просто надстройкой над ext2fs, обеспечивающей ведение журнала и
организацию транзакций. Файловые системы XFS и JFS являются
открытыми версиями коммерческих файловых систем.
2.8. Файловая система ReiserFS
Кроме проблемы быстрого восстановления после сбоев, в файловой системе
ext2fs имеется еще несколько нерешенных проблем. Одна из самых насущных -
это проблема нерационального использования дискового пространства. Конечно,
ext2fs использует диск гораздо более рационально, чем FAT, но, как
Вам хорошо известно, "памяти много не бывает"!
Собственно проблема возникает из-за следующего противоречия:
-
если размер блока выбрать большим (кластер по 32К в FAT), то при
сохранении большого числа мелких файлов на диске неразумно используется дисковое
пространство, так как маленькие файлы (и концы больших файлов) занимают целые
блоки (Juan I. Santos Florido в своей статье называет это "внутренней
фрагментацие
-
если размер блока выбрать маленьким (512 байт), то снижается
производительность ввода/вывода, так как надо прочитать много блоков, которые
могут быть разбросаны по диску (это "внешняя фрагментация").
Еще две проблемы, с которыми мы сталкиваемся в файловой системе
ext2fs,
связаны с поиском.
-
Первая проблема возникает при записи на диск нового файла.
Поскольку распределение свободных блоков хранится в виде битовой карты свободных
блоков и свободных индексных дескрипторов, то файловая система вынуждена
производить последовательный просмотр этих массивов для нахождения свободного
места. В худшем случае это может потребовать времени, пропорционального объему
диска. -
Вторая проблема поиска связана с поиском файлов в больших каталогах.
Поскольку файлы мы ищем по именам, приходится последовательно просматривать все
записи в каталоге. Время такого поиска тоже пропорционально размеру каталога и
вырастает в проблему при больших размерах каталогов.
Между тем методы снижения трудоемкости поиска давно разработаны, только надо
для хранения информации о свободных объектах использовать не простые списки, а
несколько более сложные структуры данных. В системе ReiserFS для этого
применяются так называемые "сбалансированные деревья" или "B+Trees", время
поиска в которых пропорционально не количеству объектов (файлов в каталоге или
числа блоков на диске), а логарифму этого числа. В сбалансированном дереве все
ветви (пути от корня до "листа") имеют одинаковую (или примерно одинаковую)
длину. ReiserFS использует сбалансированные деревья для хранения всех
объектов файловой системы : файлов в каталогах, данных о свободных блоках и т.д.
Это позволяет существенно повысить производительность обращения к дискам.
Кроме того, ReiserFS
является журналируемой, то есть в ней решена и проблема быстрого восстановления
после сбоев. Большего об устройстве новых типов файловых систем я пока не могу сказать,
поскольку информации о них довольно мало, а в исходниках копаться...
Литература
Костромин В.А.
Самоучитель
Linux для пользователя. ─ СПб.: БХВ-Петербург,
2003.
|
